python, 전처리, 통계, 가설검정, 기계학습, 회귀, 분류, 군집, 모델 학습, 모델 평가
차원 축소(Dimensionality Reduction)는 여러 개의 입력 변수(차원)를 더 적은 수의 변수로 변환하는 과정이다. 원본 특성을 그대로 사용하지 않고 새로운 특성(축)을 만들어 데이터를 표현하는 방법으로, 특성 추출(Feature Extraction)을 포함하는 개념이다. 차원 축소는 고차원 데이터의 시각화, 학습 속도 향상, 일반화 성능 개선에 핵심적인 역할을 한다. 이 장에서는 PCA, t-SNE, UMAP 등 주요 차원 축소 기법의 원리와 실무 활용법을 학습한다.
예제: 데이터 로드
import seaborn as snsimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.preprocessing import StandardScaler# 데이터 로드df = sns.load_dataset("penguins").dropna()X = df[["bill_length_mm", "bill_depth_mm", "flipper_length_mm", "body_mass_g"]]y = df["species"]print("데이터 크기:", X.shape)print("원본 차원:", X.shape[1])
데이터 크기: (333, 4)
원본 차원: 4
21.1 차원 축소의 개념과 필요성
차원 축소는 고차원 데이터를 저차원으로 변환하여 데이터를 효율적으로 표현하고 분석한다.
차원 축소가 필요한 이유
문제
설명
차원 축소로 해결
차원의 저주
변수가 많아질수록 필요한 샘플 수 기하급수적 증가
핵심 변수만 유지
시각화 어려움
3차원 이상은 직접 시각화 불가
2D/3D로 변환
학습 시간 증가
변수가 많을수록 계산량 증가
연산량 감소
다중공선성
상관성 높은 변수들이 모델 불안정화
독립적인 축 생성
노이즈
불필요한 변수가 노이즈 포함
주요 신호만 추출
메모리 사용
고차원 데이터는 저장 공간 많이 차지
데이터 압축
차원 축소의 기대 효과
효과
설명
데이터 구조 단순화
복잡한 데이터를 간결하게 표현
학습 속도 향상
변수 수 감소로 연산량 감소
일반화 성능 개선
과적합 위험 감소
시각화 가능
2D/3D로 변환하여 패턴 파악
저장 공간 절약
데이터 압축 효과
21.1.1 특성 선택 vs 차원 축소 (특성 추출)
특성 선택 vs 차원 축소 비교
구분
특성 선택 (Feature Selection)
차원 축소 (Feature Extraction)
정의
기존 변수 중 일부를 선택
기존 변수를 변환하여 새로운 변수 생성
원본 변수
그대로 유지
변환/조합
변수 의미
유지됨
해석 어려워짐
정보 손실
선택 안 된 변수의 정보 손실
압축 과정에서 일부 손실
예시
상관계수로 3개 변수 선택
PCA로 2개 주성분 생성
해석력
높음
낮음
적용
도메인 지식 중요
데이터 구조 의존
예제: 특성 선택 vs 차원 축소
from sklearn.feature_selection import SelectKBest, f_classiffrom sklearn.decomposition import PCA# 데이터 표준화scaler = StandardScaler()X_scaled = scaler.fit_transform(X)# 특성 선택: 원본 변수 중 2개 선택selector = SelectKBest(score_func=f_classif, k=2)X_selected = selector.fit_transform(X, y)selected_features = X.columns[selector.get_support()]print("=== 특성 선택 ===")print(f"선택된 변수: {selected_features.tolist()}")print(f"변수 의미: 원본 그대로 유지")# 차원 축소: 새로운 2개 주성분 생성pca = PCA(n_components=2)X_pca = pca.fit_transform(X_scaled)print("\n=== 차원 축소 (PCA) ===")print(f"생성된 변수: PC1, PC2")print(f"변수 의미: 원본 변수들의 선형 조합")print(f"설명 분산: {pca.explained_variance_ratio_}")
=== 특성 선택 ===
선택된 변수: ['bill_length_mm', 'flipper_length_mm']
변수 의미: 원본 그대로 유지
=== 차원 축소 (PCA) ===
생성된 변수: PC1, PC2
변수 의미: 원본 변수들의 선형 조합
설명 분산: [0.68633893 0.19452929]
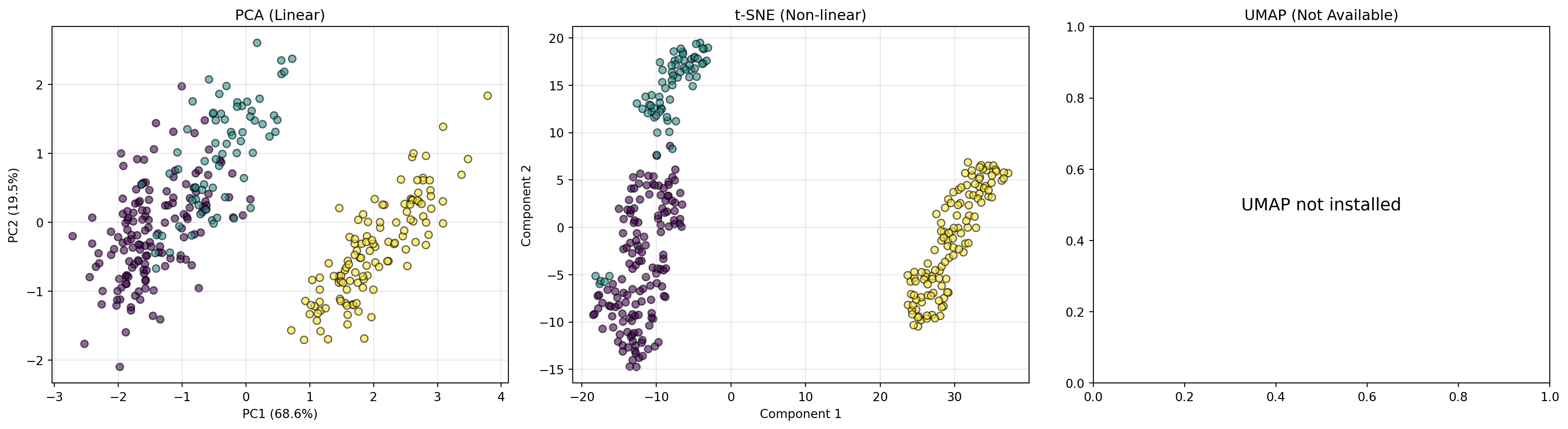
21.2 선형 차원 축소: PCA
PCA(Principal Component Analysis, 주성분 분석)는 가장 널리 사용되는 선형 차원 축소 방법이다.
PCA의 핵심 아이디어
데이터의 분산을 가장 잘 설명하는 방향을 찾음
기존 변수의 선형 결합으로 새로운 축 생성
새로운 축을 주성분(Principal Component)이라 부름
각 주성분은 서로 직교(독립)
PCA의 작동 원리
데이터 표준화 (평균 0, 분산 1)
공분산 행렬 계산
고유값과 고유벡터 계산
고유값이 큰 순서로 주성분 선택
원본 데이터를 새로운 주성분 공간으로 투영
PCA의 특징
특징
설명
선형 변환
원본 변수의 선형 조합
분산 최대화
데이터가 가장 퍼진 방향 찾기
직교성
주성분들은 서로 독립
스케일 민감
표준화 필수
비지도 학습
타겟 정보 사용 안 함
해석 가능
각 주성분의 기여도 확인 가능
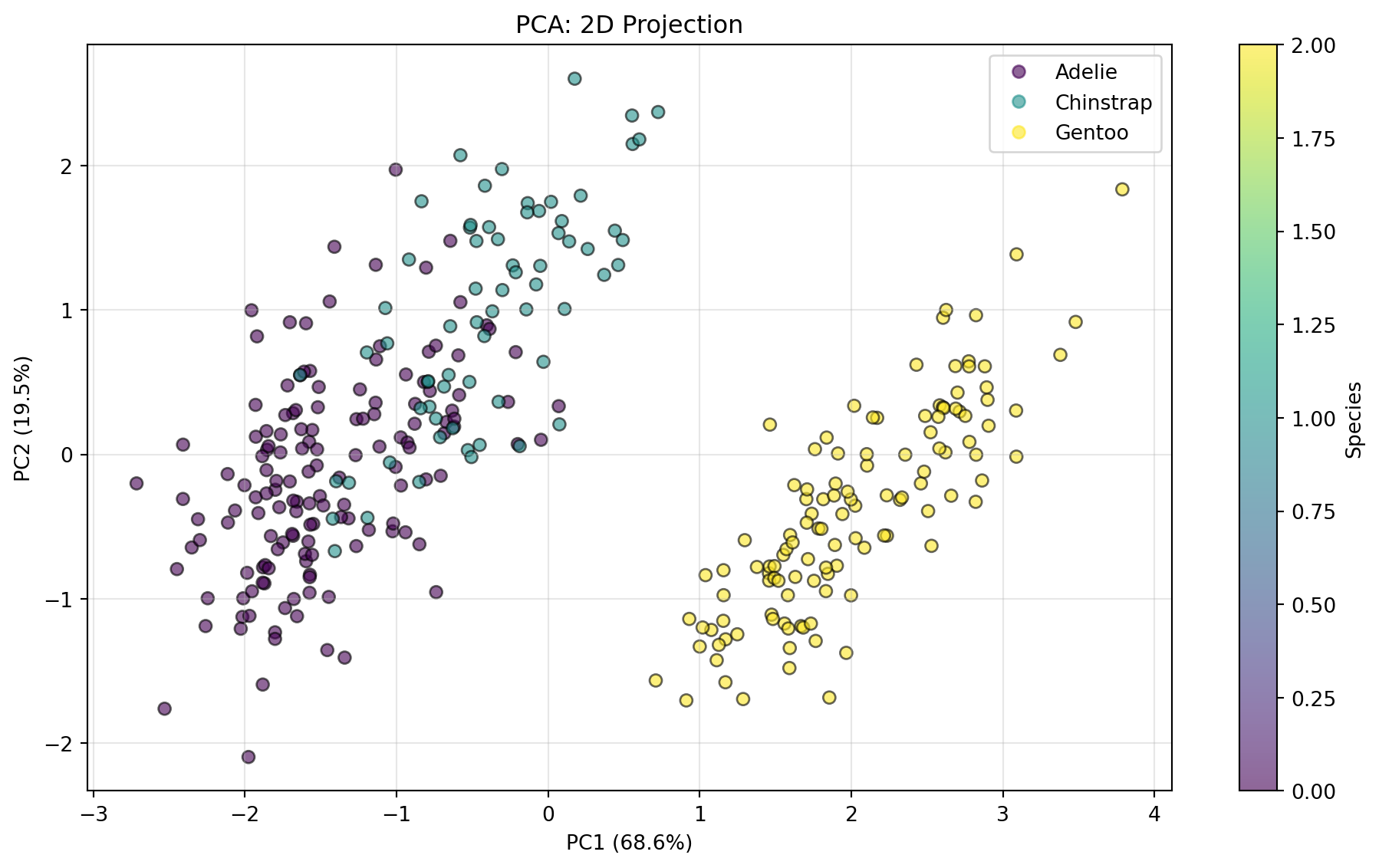
21.2.1 PCA 실습
예제: PCA 적용
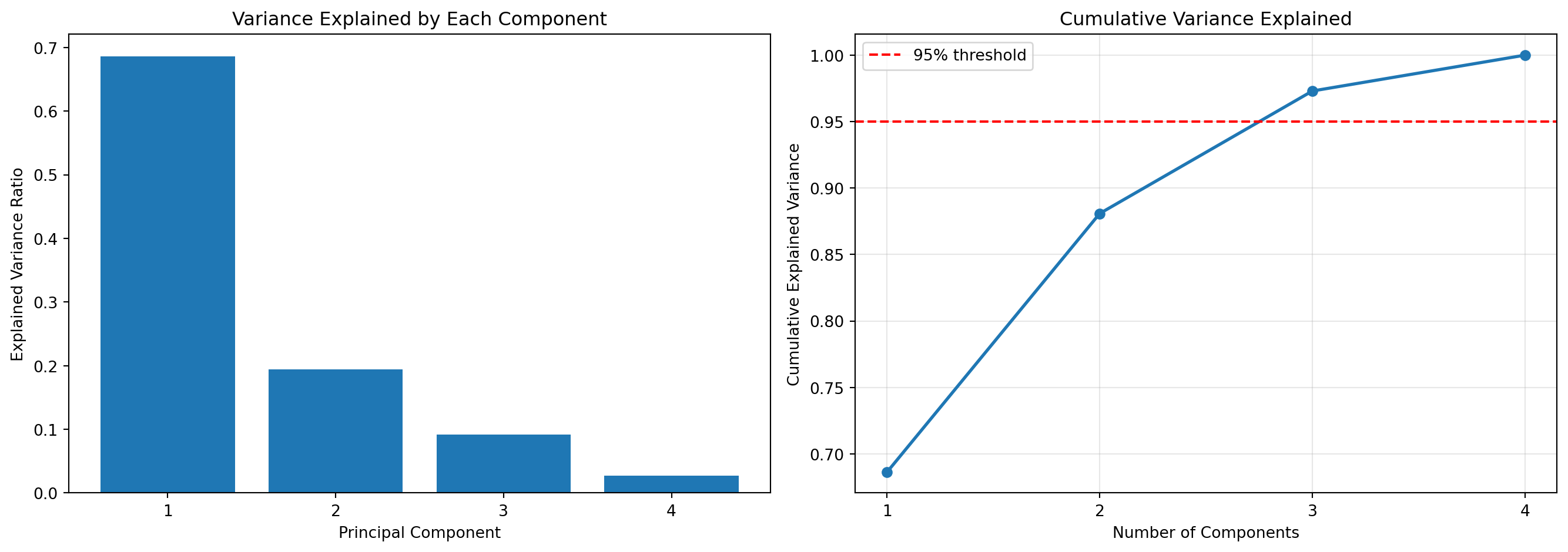
from sklearn.decomposition import PCA# 데이터 표준화scaler = StandardScaler()X_scaled = scaler.fit_transform(X)# PCA 적용 (2차원으로 축소)pca = PCA(n_components=2)X_pca = pca.fit_transform(X_scaled)print("=== PCA 결과 ===")print(f"원본 차원: {X.shape[1]}")print(f"축소 차원: {X_pca.shape[1]}")print(f"\n각 주성분의 설명 분산 비율:")for i, var inenumerate(pca.explained_variance_ratio_, 1):print(f" PC{i}: {var:.4f} ({var*100:.2f}%)")print(f"\n누적 설명 분산: {pca.explained_variance_ratio_.sum():.4f} ({pca.explained_variance_ratio_.sum()*100:.2f}%)")
=== PCA 결과 ===
원본 차원: 4
축소 차원: 2
각 주성분의 설명 분산 비율:
PC1: 0.6863 (68.63%)
PC2: 0.1945 (19.45%)
누적 설명 분산: 0.8809 (88.09%)
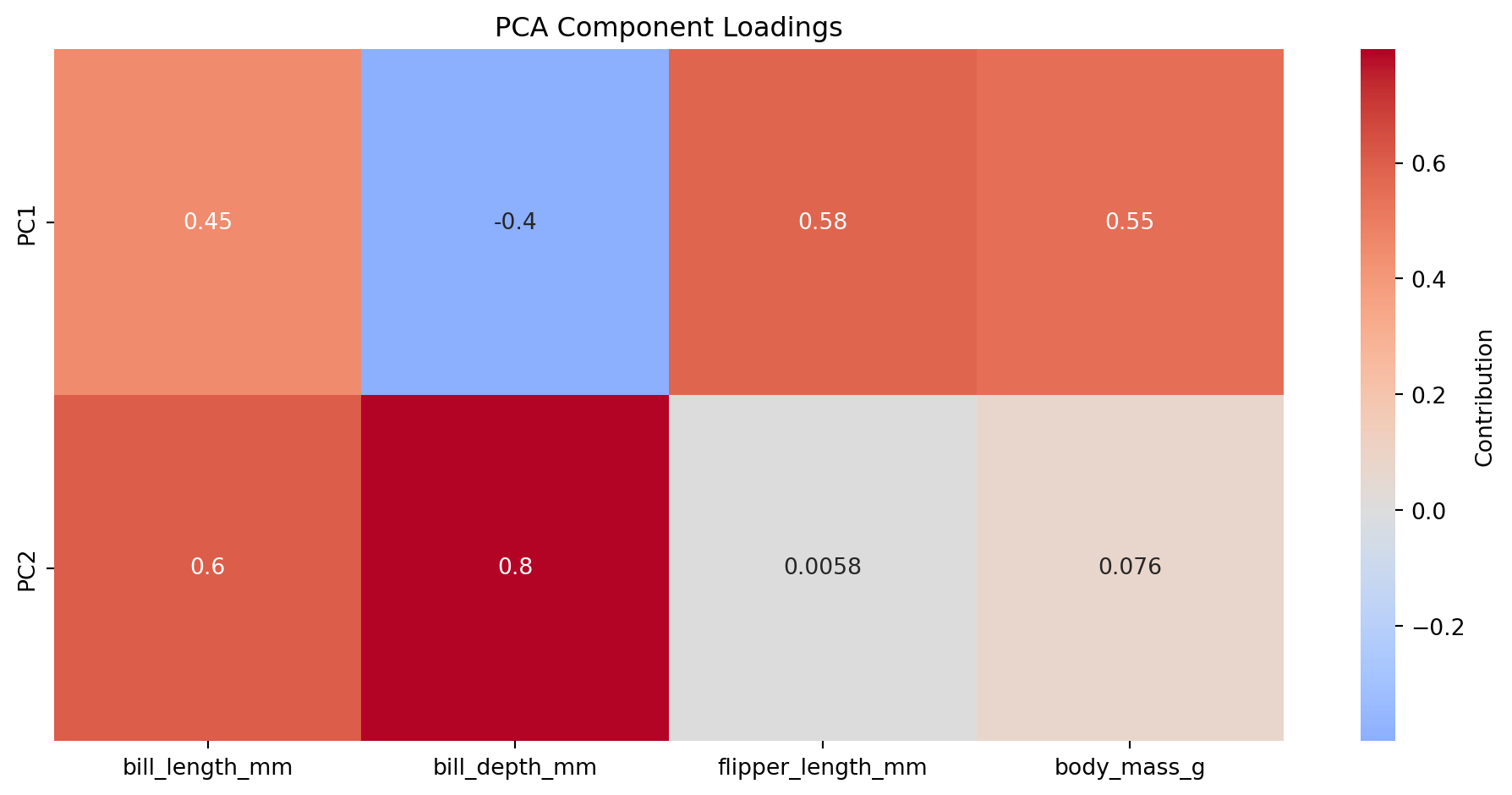
예제: 주성분 구성 확인
# 각 주성분을 구성하는 원본 변수의 기여도components_df = pd.DataFrame( pca.components_, columns=X.columns, index=[f'PC{i+1}'for i inrange(pca.n_components_)])print("\n=== 주성분 구성 (변수별 기여도) ===")print(components_df.round(3))# 시각화plt.figure(figsize=(10, 5))sns.heatmap(components_df, annot=True, cmap='coolwarm', center=0, cbar_kws={'label': 'Contribution'})plt.title("PCA Component Loadings")plt.tight_layout()plt.show()
# 95% 분산 설명하는 차원 수 자동 선택pca_auto = PCA(n_components=0.95)X_pca_auto = pca_auto.fit_transform(X_scaled)print(f"=== 자동 차원 선택 (95% 분산) ===")print(f"선택된 주성분 수: {pca_auto.n_components_}")print(f"실제 설명 분산: {pca_auto.explained_variance_ratio_.sum():.4f}")
=== 자동 차원 선택 (95% 분산) ===
선택된 주성분 수: 3
실제 설명 분산: 0.9730
21.3 비선형 차원 축소
선형 변환으로는 복잡한 데이터 구조를 표현하기 어려운 경우 비선형 차원 축소를 사용한다.
선형 vs 비선형 차원 축소
구분
선형 (PCA)
비선형 (t-SNE, UMAP)
가정
데이터가 선형 부분공간에 존재
데이터가 비선형 다양체에 존재
변환
선형 조합
비선형 변환
전역 구조
잘 보존
보존 정도 다름
국소 구조
보존 못할 수 있음
잘 보존
주 용도
전처리, 압축
시각화
역변환
가능
불가능
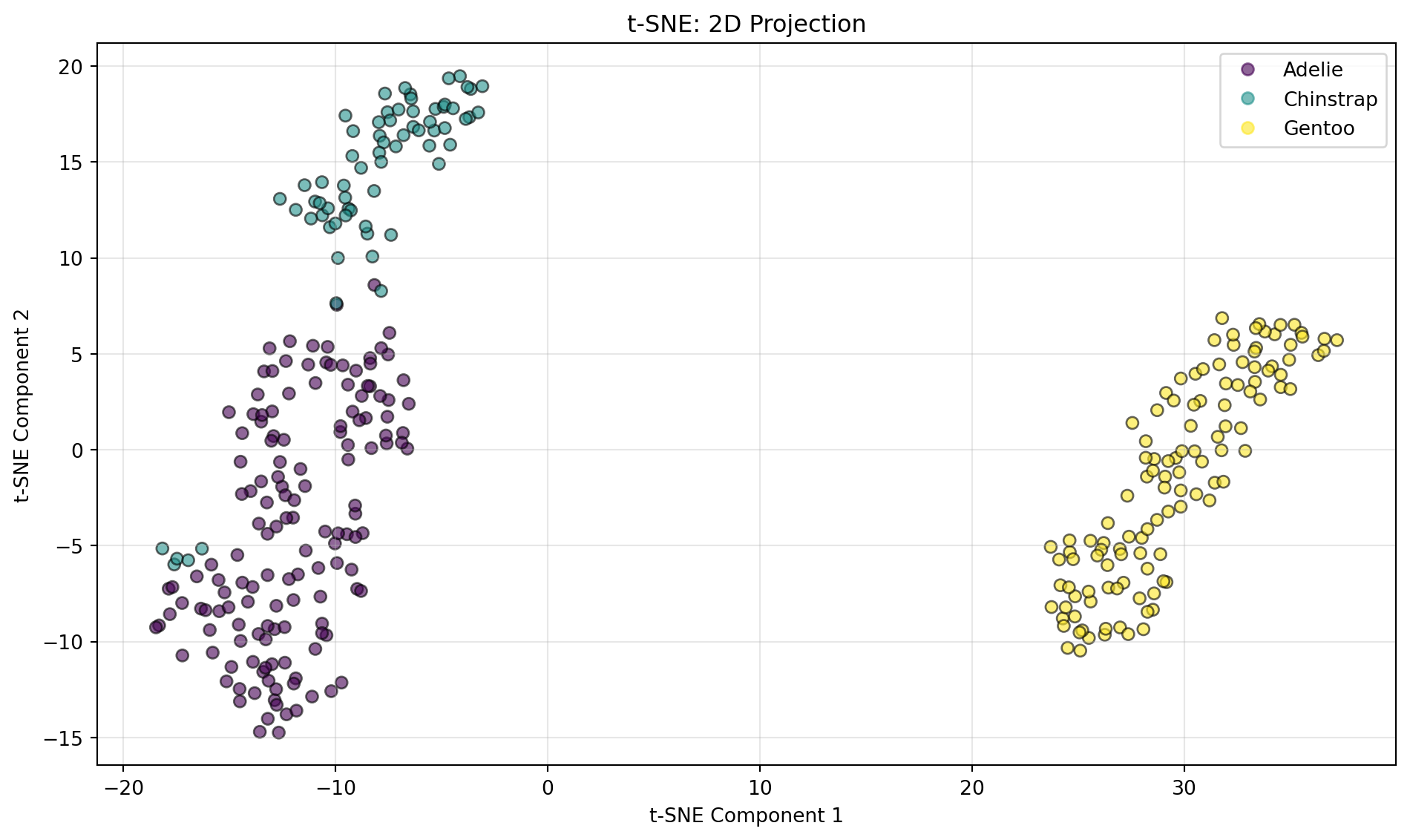
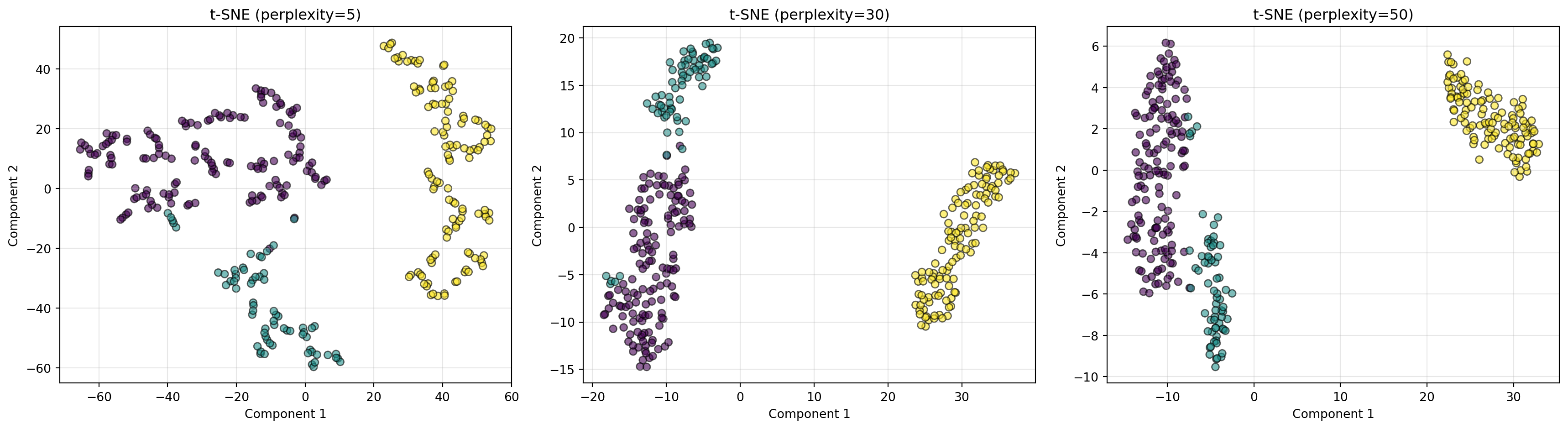
21.3.1 t-SNE
t-SNE(t-Distributed Stochastic Neighbor Embedding)는 데이터 간 이웃 관계를 확률적으로 모델링하는 비선형 차원 축소 방법이다.